前回作ったスクリプトでいろいろなファイルを暗号化して気づいたかと思いますが、単純な8bit暗号だと同じデータが並ぶ部分が丸わかりでアレ(下の画像参照)なので、まずはこの辺を隠しましょう。
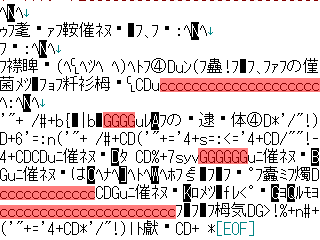
↑赤い部分は同じデータが並んでいる。別にいいかもしれないがちょっと気持ち悪い。
ファイルを暗号化するの巻・その2
というわけで、続きです。前回にあげたぶんで十分な暗号化はできますが、わかりにくくできるのならそれに越したことはないと言うことで、複雑にしてみましょう。
●とりあえずわかりづらくしてみる
前回作ったスクリプトでいろいろなファイルを暗号化して気づいたかと思いますが、単純な8bit暗号だと同じデータが並ぶ部分が丸わかりでアレ(下の画像参照)なので、まずはこの辺を隠しましょう。
↑赤い部分は同じデータが並んでいる。別にいいかもしれないがちょっと気持ち悪い。
どうするかというと、1バイトごとにキーを変化させます。例えば、こんな感じで。
| key=key+57&255 |
これを暗号化処理のループ内に放り込んでやると、1バイトコードが変換される度にキーが変化するので、同じデータが並んでいても違うコードに変換されるようになります。別に+57じゃなくても構いませんが、何となくわかりづらくなるかなーと思ったので57にしました。
で、例によって自分自身を暗号化すると、こうなります。

↑たったこれだけの変更ですが複雑になったような気がしないでもありません。
このデータをパッと見てハイフンの羅列が4カ所存在する何て誰が思うでしょうか。
●多バイト化でもっと複雑に
いくら見た目を複雑にしたところで、パスもしくはアルゴリズムが割れたらそれまでです。そこで、パスを割りにくくしてしまいます。具体的にどうするかというと、今までのキーが0~255という狭い範囲だったのを広げます。2バイトでもいいのですが、一気に4バイトにしてみましょう。これで素人が相手なら総当たりでデータを解読することは不可能と言っても過言ではないでしょう。
今「本当に不可能なの?」と思った人もいるでしょうから、それを証明することにしましょう。
まず、暗号化キーが4バイトと言うことは、組み合わせが2の32乗=約46億通りあることになります。そして、アルゴリズムはわかっているがキーと元のデータがわからないファイルの解読をしようと思ったら、どちらかを気合いで引き出すか総当たりでデコードを行いその中から当たりを見つけるしかありません。
仮にそのデコード作業がキー一つにつき10ms(=0.01秒)かかるとします。すると、全てのキーでデコードするには約1年4ヶ月かかります(笑)。さらにその中から正しいファイルを見つけなければなりません。ターゲットがBMPなどのようにヘッダの情報がはっきりしていれば最初の数バイトをデコードしてその部分において正当性をチェックすればよい為、効率が上がりますが、これがテキストファイル等だったらどうでしょう。CRCで正当性がわかればまだいいですが、目視となると・・・46億もファイルを見る人がいるとは思いませんし、それ以前にHDDがファイルサイズ*4GByte必要になるので現状ではまず入り切りません。
以上、「素人には解読不能」であることの証明でした。くどいようですが、あくまで「素人に」解読できないだけで、その筋な人から見たら楽勝かもしれませんがここでやっているのはそんな高レベルな話じゃありませんので。
というわけで、キーを4バイトにしてみました。
| key4="nケ8" ;暗号化キー repeat filesize peek src,mem,cnt ;暗号化のアルゴリズムはここに書き込む ;ここから------------------------------------------ ;暗号化・復元(排他的論理和) peek key,key4,cnt\4 dst=src^key ;------------------------------------------ここまで poke mem,cnt,dst loop |
キーが数値のままでは設定しづらいので文字列に変更します。もちろんキーボードで打てる文字が全てではないので配列変数などを利用していただいても構いません。
ここではデータを1バイトずつ読み込んでいるのでキーをバラしていますが、データを4バイト読み込んでまとめて変換しても当然構いませんし、加減算を用いて暗号化を行うのであればその方が(オーバーフローのチェックが少し面倒ですが)良いでしょう。
またまた自信を暗号化するとこんな感じになります。

なんだか、アルゴリズムが悪いせいかいまいち複雑みに欠けますね。そこで、前に書いた方法を併用しましょう。
| ;(その1) key4="nケ8" ;暗号化キー repeat filesize peek src,mem,cnt ;暗号化のアルゴリズムはここに書き込む ;ここから------------------------------------------ ;暗号化・復元(排他的論理和) peek key,key4,cnt\4 dst=src^key key=key+57&255 poke key4,cnt\4,key ;------------------------------------------ここまで poke mem,cnt,dst loop |
| ;(その2) key4s="nケ8" ;暗号化キー key4=0 repeat 4 key4=key4<<8 peek tmp,key4s,cnt key4+=tmp loop maxint=$7fffffff minint=$80000000 step=219653 repeat filesize peek src,mem,cnt ;暗号化のアルゴリズムはここに書き込む ;ここから------------------------------------------ ;暗号化・復元(排他的論理和) peek key,key4,cnt\4 dst=src^key if(key4>(maxint-step)) : key4=minint+key4-maxint+step : else : key4+=step ;------------------------------------------ここまで poke mem,cnt,dst loop |
その1がキーを1バイト*4に分解した場合、その2がキーを4バイトまとめて世話した場合です。HSPではオーバーフローすると0にリセットされるため、なんだか面倒なことをしています(そもそも、これで正しいのかな?)。


↑上がその1、下がその2で自身を暗号化したもの。だからどうしたと言われたらそれまで。
2通りの方法を提示しましたが、どちらが良いというわけではありません。好きな方を取って下さい。
ここからさらに発展させてキーを可変長にしたり、2通り以上の暗号化処理をランダムに織り交ぜてみたり、圧縮したりダミーデータを突っ込んだりすると強烈になると思いますが、きりがないのでこの辺にしておきます(可変長にするくらいなら、ちょっとの変更ですぐ実現できます)。
それにしても、画像ばかりで中身のないページだこと・・・。